标签为“Python”的页面如下
Post
淺嘗Python3.9新特性
作為一個開發人員,最好固定一段時間就去了解一下有什麼新的東西可以使用。它可能不會馬上使用到,但是有印象會加速當需要使用時,尋找的時間。
這次,稍微看了一下Python 3.9和Python 3.10的相關改動,並玩玩紀錄一下一些我認為有點意思的部份。
現在Python的更新文件幾乎都有中文版,閱讀起來並不是那麼困難,但是有部份特性並沒有說的非常清楚,還是看一下PEP和親身使用下比較明白。(隨然還是有些注意到的特性,仍不知道是要做什麼的)。
Python 3.10編譯
為此,我直接下載Python 3.10來編譯使用,順便紀錄一下編譯過程。
./confiure --prefix=`pwd`/dist/
make
make test
make install
編譯過程還算順利,除了在test階段test_os是失敗的,並跳過了20多個測試,但不影響接者的使用。喔對,不知道哪裡下載原始碼的,可以在這個頁面找到。
Python 3.9 釋出
Python 3.9於2020年10月05日正式釋出。其中主要幾個新特性包含:
Post
表示無限大。運算與比較(Python)
前言
在做LeetCode題目。然後因為我思考邏輯的關係,會需要使用到無限大(Inf)的概念,所以首先自幹的一個:
class Inf(numbers.Number):
def __gt__(self, n: numbers.Number):
return True
def __eq__(self, n: numbers.Number):
if isinstance(n, Inf): return True
else: return False
遺憾的是,這雖然可以處理Inf() > int(1),卻無法處理int(1) > Inf()的問題。無法輕易直接修改內置類型int,要是在多包一層感覺有些彆扭。所以找找看Python有沒有像EMCAScript內有Infinity的東西。可是…我第一個看的卻是日文內容。
Google中文第一個查到的也是簡體中文。要不就是Numpy的東西。
於是乎,這篇簡單的分享就出來了。
※ 最開始,我還有在numbers裡面找,無果。
Post
什麼是IIFE(Immediately Invoked Function Expression)
前言
這原本我是在Facebok一篇貼文的回應,因為覺得還蠻清楚的,所以修改過來這裡紀錄一下。(當然也可能我有理解錯誤就是)
什麼是IIFE
根據MDN是這樣寫的:
It is a “design pattern” which is also known as a Self-Executing Anonymous Function
(他又稱為 Self-Executing Anonymous Function,也是一種常見的"設計模式”)
注意 設計模式(design pattern)
這不是特指某一種技術、特性。而是思想、設計。竟然是想法,實現有差異、認知有差異可以理解的。
所以按照中文定義( 定義完馬上就執行 ),淺層廣義的來看:
function f(){};
f();
確實也是定義後執行
撰寫風格上OK,只是益處不大。
(f = function(){})() // execute first
f() // execute second
也是一樣。(這再js是合法的,之後還可以在執行f())
但就語法上就更精簡許多
從狹義、技術來看,是看是不是有附值(函式命名也是),然後才執行。 如此剛題的兩個,都是命名後才執行,狹義不算是IIFE 不過這終究只是一種設計模式,實現方式沒有一定。
function f(){};
f();
如果上面的形式,編譯器可以做優化,而直接忽略f,那他也可能是狹義的定義。
(另外這裡廣義、狹義只是我片面的解讀)
此外,在維基百科這麼寫到:
“立即呼叫函式表達式” 最早稱為「自執行(匿名)函式」 但是立即執行的函式不一定是匿名的。 ECMAScript 5的 strict mode 禁止arguments.callee 因此,這個術語不夠準確。
這或許也側面證明我的想法。
Post
關於Python Lambda那些可能不知道的三兩事
lambda本質和function無異
def f():
pass
type(lambda : None) # => <type 'function'>
type(f) # => <type 'function'>
lambda :None # => <function <lambda> at 0x7ffa6d343650>
f # => <function f at 0x7ffa6d349dd0>
lambda和function的型態都是function,並沒有區分開來。
一個是語句、一個是表達式
差別在於def是關鍵字形成的語句(statement),lambda是表達式(expression)。他們差別在於,能出現在程式碼的不同位置。
※ Note: 表達是(expression)也是一種語句(statement)。為了簡單來看,接下來都會區分開來。
內建有多個函式可以接受函式參數
因為lambda和function本質差無異,所以不會有函式只可以接受lambda,不可以接受function。
filter(lambda parameter: expression, iterable)
filter(function, iterable) # more correct
比起使用lambda描述filter,用function更正確。reduce等也是這樣。
lambda多行的寫法
通常看到lambda都只有一行,正常情況下也都是這樣。不過先來看看文件怎麼描述lambda的語法:
lambda_expr ::= "lambda" [parameter_list] ":" expression
lambda_expr_nocond ::= "lambda" [parameter_list] ":" expression_nocond
相當於:
def <lambda>(parameters):
return expression
Post
【微更】你可能沒看過得Python - Callable(續)
【微更】Callable的實現
之前我實現了Callable Class,當時對於CallableWrapper的實現如下:
class CallableWrapper:
def __init__(self, wrap):
self.wrap = wrap
def __call__(self, f=None, *args):
if f == None:
return self.wrap
return CallableWrapper(f(self.wrap, *args))
這個實現有一些缺憾,CallableWrapper的__call__回傳值,也是CallableWrapper。而CallableWrapper本身預期被呼叫,這導致結果不能直接使用,需要多給一次空呼叫(result())。舉例來說:
arr = CallableWrapper([1,2,3,4,5,6,])
arr # => <__main__.CallableWrapper object at 0x7f2102f00668>
# arr(sum) + 10 # You can't do this, because CallableWrapper can't add integer
arr(sum)() + 10
上例中,並不能直接寫arr(sum) + 10,要寫arr(sum)() + 10。這感覺有點脫褲子放屁阿…
基於此想法,我改寫成:
Post
MyString委派(delegate)加法
之前擴展String的+方法。不過這樣的實現不是很彈性:
count = 10
"-"*10
# "Count: " + count # will rise exception
"Count: " + str(count) # allow string + string
class myString(str):
def __add__(self, other):
if other == None:
return myString(str(self) + "None")
elif type(other) == str:
return myString(str(self) + other)
elif type(other) == int or type(other) == float:
return myString(str(self) + str(other))
else:
return myString(str(self) + str(other))
myString("Count: ") + count # success. => 'Count: 10'
myString("Count: ") + count + " and " + count # => 'Count: 10 and 10'
myString("Count: ") + None # => 'Count: None'
這次來稍微修改,改用委派的方式。
Post
Python的資料模型(Data Model)的特殊成員(Special Member)
上一篇寫到,覆寫Python操作子(Override Operator)。其中提到operator這個Package,並對類別實現特殊方法,來覆寫運算子的行為。不過這麼寫不完全正確,只是Operator Package的頁面清楚的多,而這覆寫的動作,實際更直接與Python資料模型中的特殊成員(特殊屬性&特殊方法)(Data Model - Special Member(Special Attribute & Special Method))相關。

Post
Python的函數(Function)vs方法(method)
前言
※ 本段有些難度,略過並不影響後續理解。
在幾天前,我實現了一個可以傳入函數呼叫的類別(Callable Class),相關可以參考「用Python實現Callable Class」。
起初,我實現Meta-Class的方式,是在defineclz.__new__(clz, *args, **kwargs)實例(instance)後,將實例增加函數成員(Function Member)。不過這樣做並不太成功。會需要使用instance.__call__(f, *args, **kargs)去執行。而直接複寫defineclz.__call__的話,以會造成不斷呼叫的問題,而且無法讓後續繼承子孫,再進一步調整方法。這也是為什麼後來以內部類別實現,並且另擁有__call__能力的類別,後於defineclz,好讓自定義的__call__可以複寫掉預設行為。
※ Note: 本文寫到的函數成員(Function Member),主要是指實例屬性,但這個屬性是一個函數。更多時候,成員(Member)可能就包含方法(Method)和屬性(Attribute),而函數成員(Function Member)可能就直指方法(Method)。
定義方法(method)vs定義函數(function)
※ 尚為去翻找文件,可能有錯誤。
在Python,可以用def關鍵字去定義一個函數:
def f1():
print("call f1")
f1()
而方法的定義也是使用def:
class C1:
class_attr1 = {}
def __init__(self):
self.instance_attr1 = {}
def _f1(self):
print("C1: f1")
def f1(self):
self._f1() # if wrote `_f1()`, it will not found
def f2(self):
def _f2():
print("C1.f2: _f2")
_f2()
c1 = C1()
c1.f1()
c1.f2()
但其實這裡就可以看出一些行為的不同。上面_f1()和f1()看是在同一個scope,但是如果f1()需要呼叫_f1(),必須使用self._f1()或是C1._f1(self),如果直接寫_f1()會報錯說找不到。相對來說f2()是C1類別的方法,但是內部函式_f2不是,因此就不需要這樣寫。現在在把f1()移出類別外,變成一般函式看看:
Post
用Python實現Callable Class,FP更好寫
This Article has English Version, please goto here to read.
前言
最近,和朋友們在解LeetCode的題目。看著不同人寫出來的程式,也讓我對於一個題目的解法,有更寬廣的視野。
938. Range Sum of BST
URL: https://leetcode.com/problems/range-sum-of-bst/
這篇文章與這個想法,也是受到朋友寫的一個Ruby寫法的啟發。我用同樣的邏輯去寫Python,如下圖:
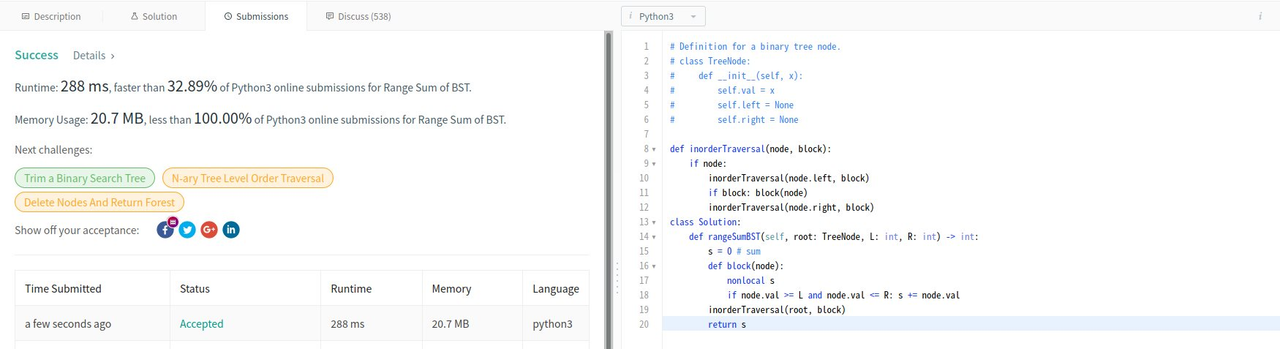
當然,這題目有更好更快的寫法,但這樣寫更為有趣有意思。
但是,內部隱含的block函數,從函數型語言的設計原則來看,他是危險、骯髒的。這是因為每次他的執行,都會修改到外部變數s的的值。(這辦法不夠 純函數 )
因此,我修改成以下方式:

如此,你還可以改寫成一行:
Post
關於Python 3.8的象牙運算符(:=)
我沒想到一天會來寫個三篇😅。不過看完PEP 572 and The Walrus Operator後,對於象牙運算符(:=),稍微產生了點不同樣的看法。至於稍早前覺得蠻新鮮的想法…可以去看看我上一篇。
此外,感謝Chang-Ning Tsai在社團分享該篇文章。
有爭議的象牙運算符(:=)
it is ambiguous for developers to distinguish the difference between the walrus operator (:=) and the equal operator (=). Even though sophisticated developers can use “:=” smoothly, they may concern the readability of their code.
最近在解LeetCode,在沒有這個賦予值的方法前,真覺得有些時候有點不方便。可是這個運算符在是否納入時,似乎有引起一些爭議。像是:=可能難與閱讀,不過我覺得比較有問題的還是賦予值運算子(=)和象牙運算子(:=)的混搖,更正確的說,我是覺得兩者有點太像,這似乎有點違反Python的則學之一:「There should be one– and preferably only one –obvious way to do it.」,用同樣的方式做事。
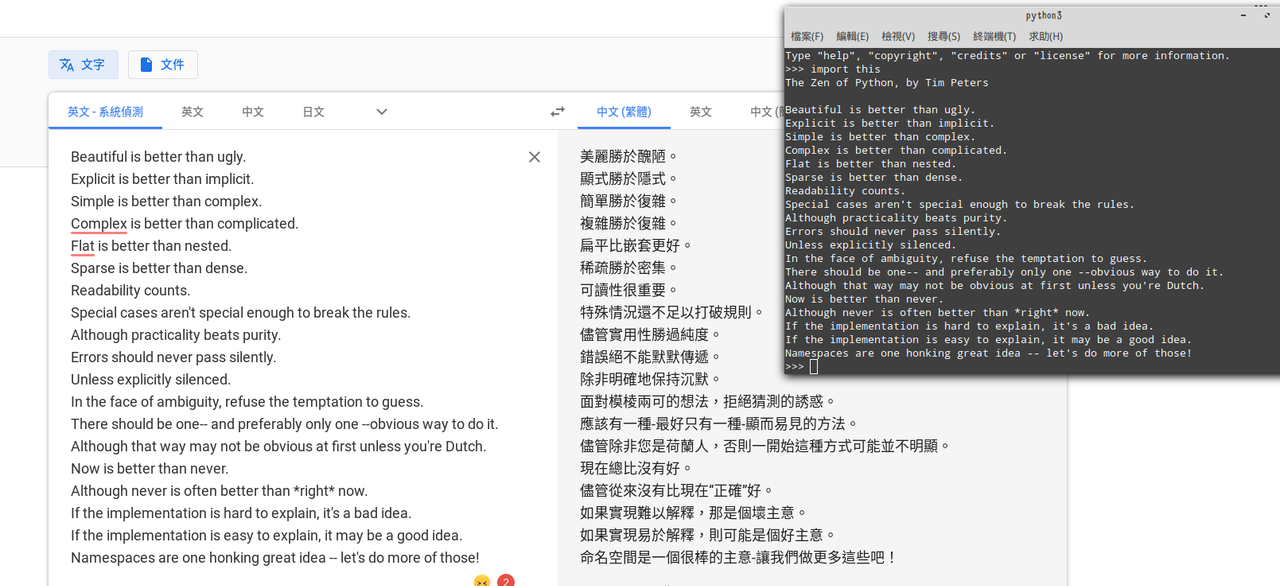
然後,不好意思,有一條是怎麼回事?
Although that way may not be obvious at first unless you're Dutch.
Dutch怎麼了嗎?
繼續深入
Developers may confuse the difference between “:=” and “=.” In fact, they serve the same purpose, assigning somethings to variables. Why Python introduced “:=” instead of using “=”? What is the benefit of using “:=”? One reason is to reinforce the visual recognition due to a common mistake made by C/C++ developers. For instance,
int rc = access("hello_walrus", R_OK);
// rc is unintentionally assigned to -1
if (rc = -1) {
fprintf(stderr, "%s", strerror(errno));
goto end;
}
Post
Python3.8的幾個我覺得有意思的新特性
Python 3.8同樣有不少變動,有些蠻細微的,需要詳細了解可能還是直接看Python 3.8 有什么新变化der好。現在文檔都有(簡體)中文版,覺得比英文好讀多了。所以這篇只會分享幾個我覺得有意思的新特性。
遺憾的是,我還沒有更新到3.8,只能看看而已😭。
f-Strings
這個特性我單獨寫了一篇,歡迎看看:Python-3.8後的f-String。
象牙運算符(:=)
18:00更新
關於這看起來有點好用的東西,在做了更深一步的了解,可參考:關於Python 3.8的象牙運算符(:=)
寫過Golang的同鞋,對於這個運算符應該蠻熟悉的,這另這兩個語言有自動推導類型的能力。不過在Python裡,是相較於asign運算符(=),象牙運算符(:=)更像表達式(expression),而非語句(statements)。要我寫的話,偽代碼可能有點像:
※ Note: 表達式(expressions)也是一種語句(statements)。表達式會嘗試求值,但是語句不一定。此處主要是想表達 象牙運算符(:=) 會嘗試求值。
# @symbol var
def :=(val):
nonlocal var
var = val
return var
賦予完變數值後,返回變數的值。這麼一來可以寫在任何需要表達式的地方(如果我沒理解錯的話0.0)。來看幾個文件上的範例:
if (n := len(a)) > 10:
print(f"List is too long ({n} elements, expected <= 10)")
原本f-Strings裡可能要寫"{len(a)}",但是這樣做的話就無須在對len(a)求值一次;或是在外圍設定變數值n = len(a)。(儘管最近觀察,內置內行的len(var)求值,可能還比賦予值(=)消耗成本還低)
接下來這例子就讓我真的很想用了:
# Loop over fixed length blocks
while (block := f.read(256)) != '':
process(block)
我一度在想會不會有while expr as var:的語句。雖然沒有,不過用:=可以更為靈活。
PEP 578: Python 運行時審核鉤子(Runtime Audit Hooks)
Post
Python-3.8後的f-String
近況
最近在翻itertools、collections,和已經很常在用,但想看看還有啥的functools。這裡頭的東西並非必須,大部分我都有能力自幹。但沒必要再造輪子,甚至可以從此獲得一些啟發。譬如,itertools.groupby,我看到第一個想法就是:「這不就可以更簡單實現Hadoop裡,Map-Reduce分組的功能?」。於是乎就寫了下面一段程式:
from itertools import groupby
from functools import reduce
a = [1,2,3,4,5,6,7,8,9,]
def pipe(data, *process):
result = data
for proce in process:
result = proce(result)
return result
p = pipe(a, lambda x: map(lambda y:y**2, x),
lambda x: sorted(x, key=lambda y: y%2),
lambda x: groupby(x, key=lambda y: y%2),)
for g, d in p:
l = list(d)
s = sum(l)
print("{g}: {d}, sum:{s}".format(g=g, d=l, s=s))
不知道python有沒有
pipe的內部實現?
這段程式碼是將list a裡的奇數和偶數分組取平方加總。比較麻煩的是groupby依照官方文件寫法,相當於以下程式碼:
class groupby:
# [k for k, g in groupby('AAAABBBCCDAABBB')] --> A B C D A B
# [list(g) for k, g in groupby('AAAABBBCCD')] --> AAAA BBB CC D
def __init__(self, iterable, key=None):
if key is None:
key = lambda x: x
self.keyfunc = key
self.it = iter(iterable)
self.tgtkey = self.currkey = self.currvalue = object()
def __iter__(self):
return self
def __next__(self):
self.id = object()
while self.currkey == self.tgtkey:
self.currvalue = next(self.it) # Exit on StopIteration
self.currkey = self.keyfunc(self.currvalue)
self.tgtkey = self.currkey
return (self.currkey, self._grouper(self.tgtkey, self.id))
def _grouper(self, tgtkey, id):
while self.id is id and self.currkey == tgtkey:
yield self.currvalue
try:
self.currvalue = next(self.it)
except StopIteration:
return
self.currkey = self.keyfunc(self.currvalue)
Post
深入了解scikit Learn裡TFIDF計算方式
TFIDF計算說明
參加今年iT鐵人賽時,曾經寫過簡單使用scikit-learn裡的TFIDF看看,並寫到scikit-learn裡tfidf計算方式與經典算法不同。後來在官方文件中找到說明,也簡單嘗試了一下。這次來做點分享。
在經典算法,TF是這樣計算:
n_(i,j),也就是使用CountVectorizer的結果。
IDF的部份,原本經典算法是:
log(n/(df(k)+1))計算,也就是將分子+1。scikit-learn裡面則分成兩種,預設使用smooth的版本:log((n+1)/(df(k)+1)),也就是分子分母都加一;另一種是經典原始版本,而外加上1:log(n/df(k))+1。
最後sckit-lean會做標準化(normalize),所以最後結果會是normaliz(tf*idf)。
嘗試實驗
引入套件
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
import math
from sklearn.preprocessing import normalize
實驗資料
d1 = 'a b d e d f a f e fa d s a b n'
d2 = 'a z a f e fa h'
d3 = 'a z a f e fa h'
對,基本上就是簡單使用scikit-learn裡的TFIDF看看所測試的方式,所以當然也要將stop_words=None, token_pattern="(?u)\\b\\w+\\b"而外設定,原因這裡就不多做說明了。
Post
Python在3.6後幾個便利的新變化
前言
這幾天又看了/試了不少東西喔。雖然也開始往下一個階段進行, 但興趣的事情,還是添加不少東西能來寫下隨筆。
這次的話題與前幾篇–JShell?-程式語言越來越像Lisp有關。 在那篇我留下了不少以後可能回來談談的話題,包含:
- JAVA版本之謎。
- 為什麼不使用LISP?
關於第一點,我打算去編譯看看幾個我挺喜歡的軟體再來說說感想, 但幾日前在Medium看到一篇文章。裡面有張圖片這麼形容JAVA:
{kind=link}
JAVA騎士要去救城堡裏的公主,他很快的完成裝備前往救援,但是 他發現竟然有兩個 不同版本的城堡,重點是裡面沒有公主 。
Python 3.6之後LAG覺得有用的幾個新特性
已經忘記原因了齁,但數天前又LAG跑去看Python Whtat's news。 今天來分享幾個又LAG覺得非常有用的新特性。
不過很可惜的,又LAG主要的電腦還停留在 Python 3.5.2
。要更新到新版本需要自行編譯,還好目前沒有這樣特別的需求,
並且筆電與虛擬機都是使用 3.6 或之後的版本,可以說如果你是安裝
Ubuntu 16.04 之後或其衍生版,應該內建的都是 3.6 之後的版本了。
至於Windows的用戶應該可以直接在官網下載安裝包。
Post
實現Python裏面的classmethod和staticmethod
在Python裏面存在著兩個用於定義物件方法的內建函式(built-in function) – classmethod和staticmethod。其實我一開始在學的時候根本沒用過他們(´・ω・`),先不管他們常不常用,雖然應該就是常用所以才會被放進內建函式,不過因爲常見的特殊語法–修飾器,使得隨後定義的方法與實際作用變得不同,常讓初學的人摸不著頭緒。今天就來以實現說說這兩個函式。
預備知識
首先你要先有基本的Python概念。接著最好已經很瞭解 修飾器 的作用。如果不瞭解修飾器,強烈建議先閱讀函式修飾器。 雖然本文在最後也爲實現一個相似於修飾器的函式版本 – [wrap](#修飾器的作用與實現 – wrap) ,不過其又涉及到其他知識,並不建議直接閱讀。
Check List
- 我瞭解最基本Python
- 我知道Python裏面修飾器的作用
實現classmethod和staticmethod – MyClassmethod, MyStaticmethod
在實現之前,必須先瞭解classmethod和staticmethod有甚麼特性?在使用後會發生什麼事情?
一般而言,在定義物件方法時會給與def methodName(self, *args, **kargs),其中self表示物件實例本身。如果你瞭解 Lua 會發現是同樣的顯式引用發法,並且Lua中的語法糖instance:method(...)(相當於class.method(instance, ...)),幾乎就對應於Python裏面的Instance.method(*args, **kargs)(相當於Class.method(Instance, *args, **kargs))。
相較之下,C++、Java裏面的this,或是VB裏面的Me,就是隱式用法。我自己是比較喜歡顯式引用,比較明確。